




祝!書籍化!!
「大学生のための」を中心にしていますが、社会人の勉強などにも役立つ内容がたくさん書いてあります。筆者が医学生〜医師としての過程で獲得した効率の良い勉強法についても盛り込んでありますので、ぜひ手に取ってみてください!


祝!書籍化!!
「大学生のための」を中心にしていますが、社会人の勉強などにも役立つ内容がたくさん書いてあります。筆者が医学生〜医師としての過程で獲得した効率の良い勉強法についても盛り込んでありますので、ぜひ手に取ってみてください!
教科書をスキャンしてPDF化すればタブレットに入れていつでも読むことが可能です。この記事では、本の章構造ごとに分割してスキャンする方法を紹介します。
今回は教科書のPDF化の過程のうち、スキャンの方法を紹介します。スキャンした後にPDF Expertで読んでいくことも考慮して行う工夫についても紹介します。
今回使用するスキャナーはEPSON製のDS570Wという機種です。
 筆者
筆者この記事は教科書のPDF化シリーズの1つです!
↓シリーズ記事の順番に読んでもらうのがおすすめです。
この記事より前の段階までで裁断についての紹介は終わっているので、本が分解されて紙の束になっている状態から説明していきます。
裁断まで終わったら最後はスキャンの過程です。
筆者は裁断の過程は業者にお願いしているので、かなりきれいに仕上がってきます。
さて、スキャンは普通1冊の本を1つのPDFにまとめてスキャンすると思いますが、筆者の場合には本の章ごとに分けてスキャンしています。
この理由としては、
筆者が利用しているスキャナーはEPSONのDS-570Wです。
一番メジャーな機種というわけではありませんが、高機能で使いやすい機種です。
メジャー機種のScanSnapよりちょっと安いです!
パソコンを持っているなら性能に大きな差はなくお買い得な製品
一番メジャーな機種はコチラのScansnapです。
ScanSnapは本体にディスプレイがついていて使いやすいのが魅力です。
https://digista.net/2020/01/26/scansnapix1500/”,”text”:”ScanSnapiX1500をiPad勉強家が買ってみたレビュー”} /–>裁断の方法は別の記事でまとめてあるので、こちらを御覧ください。
https://digista.net/2018/05/03/saidan-daiko/”,”text”:”教科書のPDF化(自炊)の方法〜裁断業者編への依頼方法〜”} /–>▼裁断した教科書はこのような紙の束になっているはずです。

先程も紹介したように筆者の場合はざっくりと、章ごとにわけてPDF化していきます。
もちろん普通に1冊まとめてPDFにしてもOKです。
次にすることは本の目次をみて本の構成を調べます。
この本の場合には、
・総論
・各論
・精神医学と社会
という3つに大きく分かれることが分かりました。
この本は300ページほどの薄い教科書ですので、3つにざっくり分けることにしました。
一番右側の束は、タイトル、序文+目次の束です。

ハリソン内科学といった3000ページくらいの教科書の際には20くらいの章に分けてスキャンしています。
筆者この本の構造を調べる過程が意外と読むときにも役に立ちます。
大まかな外枠をしることができるので、読みやすく、頭に入りやすくなるのです。
スキャナーは普段はコンパクトに収まっていますが、展開すると大きくなります。
▼普段はコンパクト:横の水は大きさの参考用


DS570Wでは専用ソフトで色々設定ができます。
使用しているPCはMacなので画像はMacでの設定画面になりますが、Windowsでも同じ様な設定が行えるはずです。
専用ソフトはDocument captureというソフトです。
▼管理画面はこんな感じ
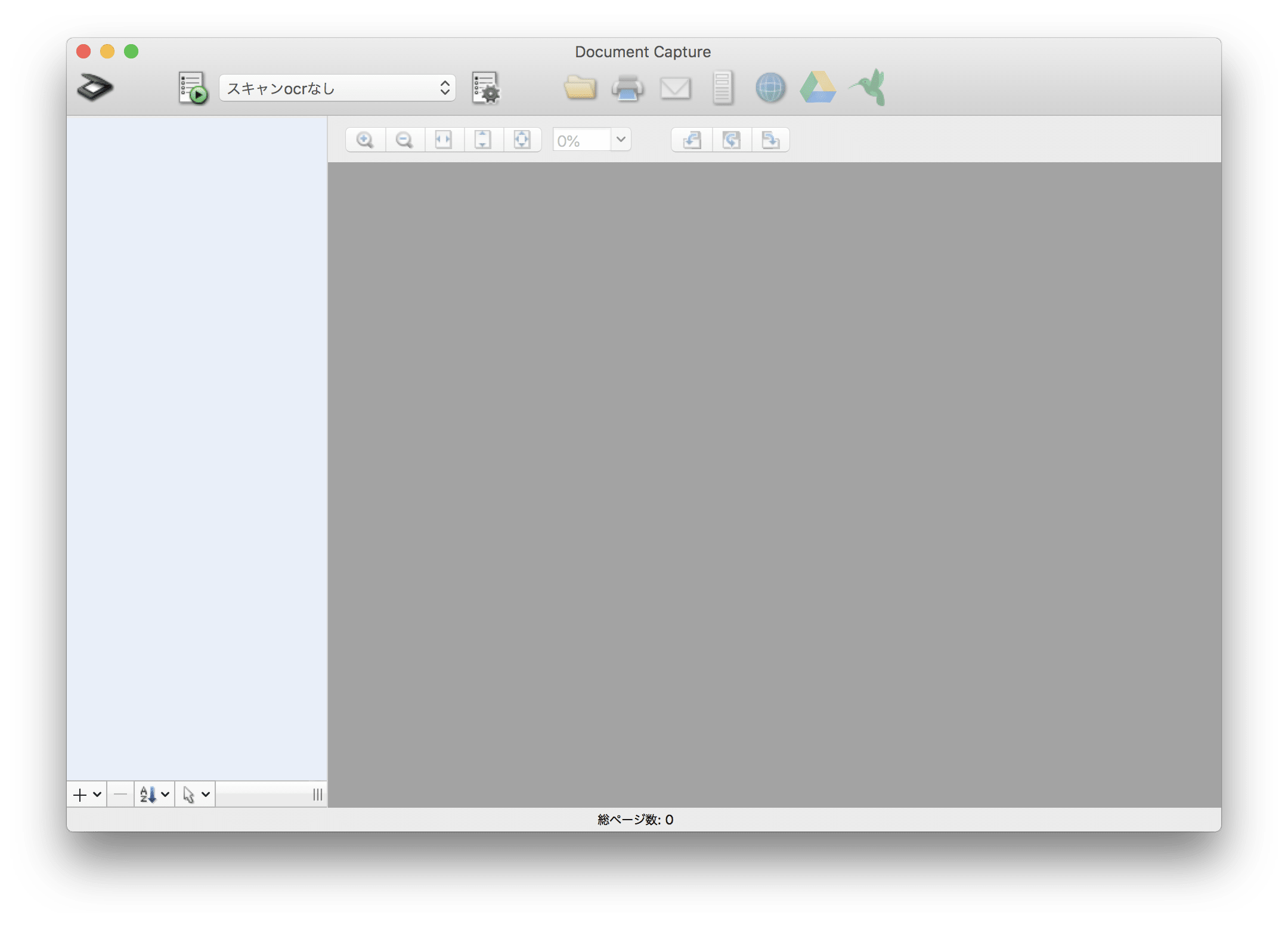
▼ジョブリストという設定を保存する機能が有ります。
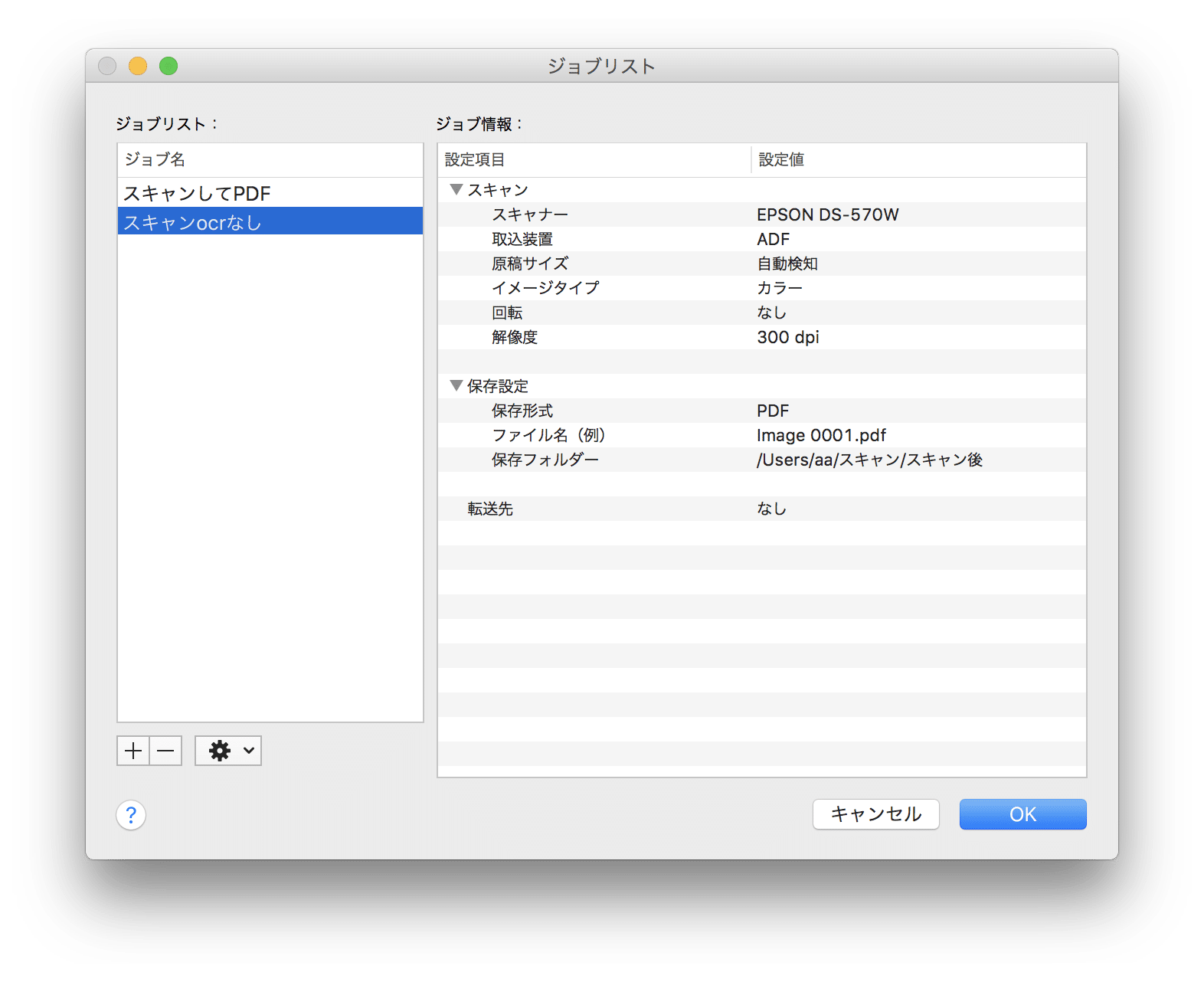
筆者の場合はスキャンの方法は上の画像の1パターンだけにしています。
(1つ目はデフォルトの設定)
筆者デフォルトでも全然問題なくスキャンが可能です。特に難しい設定はしていません。
解像度をデフォルトの200dpiより上げているのは将来的にディスプレイが更にきれいになった場合を想定しています。
デフォルトと替えているのは保存フォルダの指定と解像度の変更です。
実際にスキャンしていきます。
筆者が使用しているようなスキャン専用機なら、紙の束をドサッとセットして開始ボタンを押すだけで連続でスキャンしてくれます。
digi(筆者)
一枚一枚手差ししていると思われる方もいるようですが、違いますからね!
先程、4つの束に分けた書籍の中で最も分厚い束が160ページありました。
今回使用しているDS570Wでは160ページ分も一気にセットできます。
紙の質にもよりますが、160ページ+であと10ページ分ほどセットできそうです。
筆者このようにスキャナーに一気にセット可能な枚数は150〜200枚程度です。書籍を1冊まるごとスキャンしようとしても、何回かに分けてセットする必要があります。なので、内容ごとに何部かに分けてスキャンを行ったとしても労力に大きな差はありません。
スキャンしてます。こちらがEPSONのDS-570Wのスキャン速度です。
pic.twitter.com/apkiGatD0A
△こんな感じでスキャンしていきます。
今回は1冊の本を4つの束に分けてスキャンを行ったので、4つのPDFができました。
スキャンを行う際にもコツがあります。
これを知っているか知らないかではスキャンにかかる時間も違うかもしれません。
一度スキャンをしたことのある方にならわかって頂けると思うのですが、スキャンし終わった紙の束はものすごいバラバラできれいに元の状態にまとめることが困難です。
きれいにまとめようとしても紙の摩擦で全然まとまってくれません。
そんなときに覚えておいてほしい方法がコチラです。
ざっくり言葉で説明すると「息を吹きかけながら揃える」 という感じです。
紙同士が静電気でくっついているので、摩擦が大きくなっている状態なので、空気を送り込んで紙と紙の間を空けて上げれば摩擦力が下がってきれいに揃うという感じでしょうか。
ここまででスキャンしたPDFは「写真」の状態です。
ですので、検索しても引っ掛けることはできません。
検索できるというのも教科書をPDF化するメリットですので、文字認識処理(OCR処理)はぜひ行っていきたいところです。
文字認識には専用のソフトが必要です。
スキャナーについているDocument captureにもOCR機能はありますが、筆者はこれとは別にAcrobat Proというソフトを購入しました。
Macでも使えるOCRソフトは選択肢が少ないです。
Windowsの方はもっと選択肢があると思いますす。
[amazon asin=”B0771JTRDQ” kw=”Adobe Acrobat Pro DC 12か月版(2019年最新PDF)Windows/Mac対応オンラインコード版”]スキャナー附属ソフトでもできることをわざわざ別のソフトでおこなう理由は、
時間のため
です。
なぜ文字認識ソフトによって時間の差が生じるのか説明させてください。
まず重要な前提として、文字認識処理にはかなり時間が掛かります。
パソコンのスペックにもよると思いますが、スキャンにかかる時間を1とすると文字認識処理には10以上の時間が掛かります。(Mac Book airを使用)
スキャナー附属のソフトを使用した場合、スキャンの直後に一連の流れとして文字認識処理を行う必要があります。(スキャナー附属のソフトの都合です。)
スキャン直後に文字認識を行うと連続してスキャンを行うことはできません。
これでは1部スキャンするたびに、かなりの待ち時間が生じます。
これを別のソフトで行うと、スキャンが終わったPDFをまとめて文字認識処理することができます。
夜寝る前に複数のPDFを指定して処理開始しておけば、朝起きたら文字認識が完了しているという便利さです。
▼Acrobat Proの操作画面
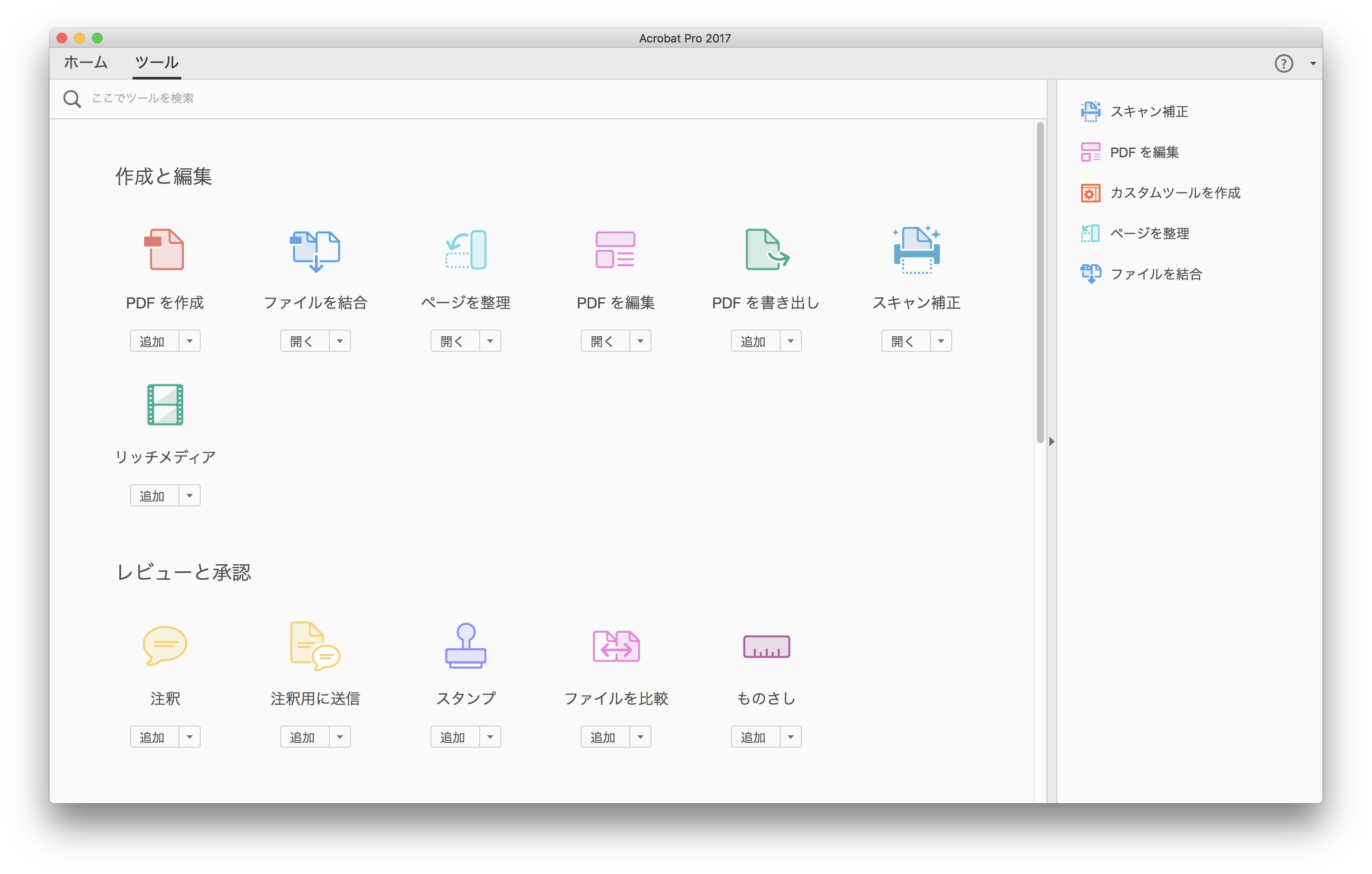
PDFの中の文字を認識するにはこの中の「スキャン補正」という項目を使用します。
▼スキャン補正の画面です。
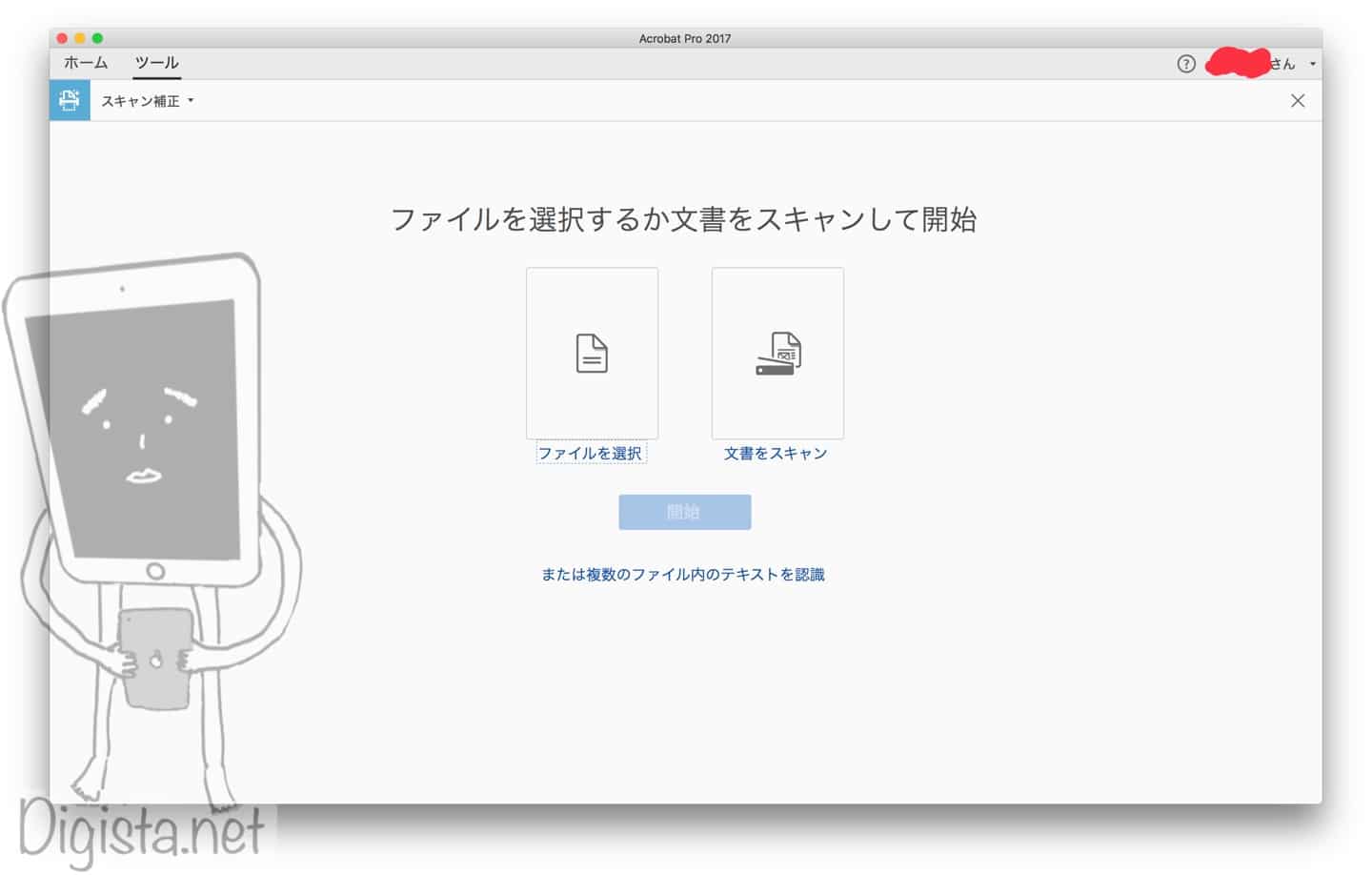
ここで「複数のファイル内のテキストを認識」をチェックします。
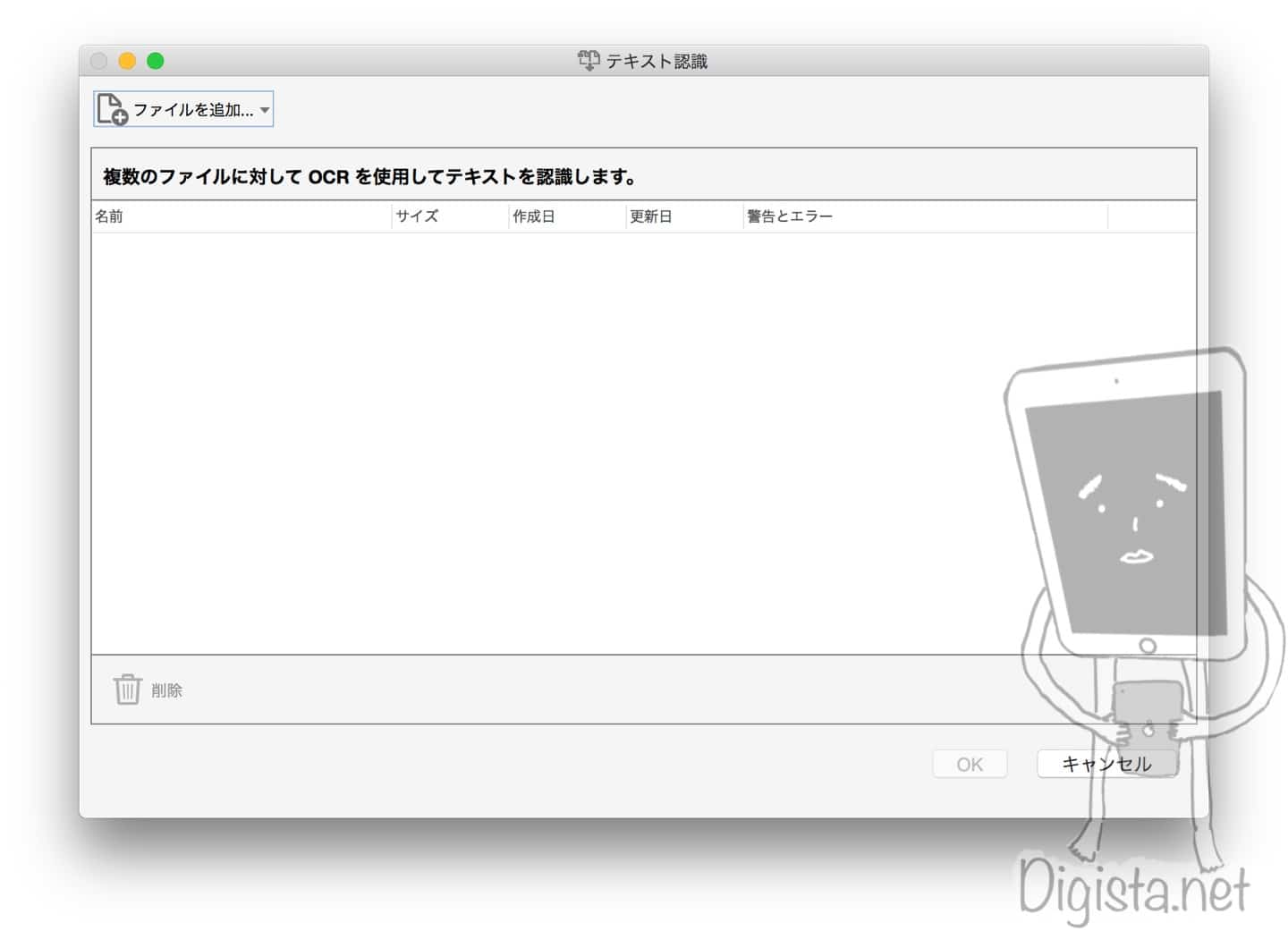
「ファイルを追加」をクリックすると、
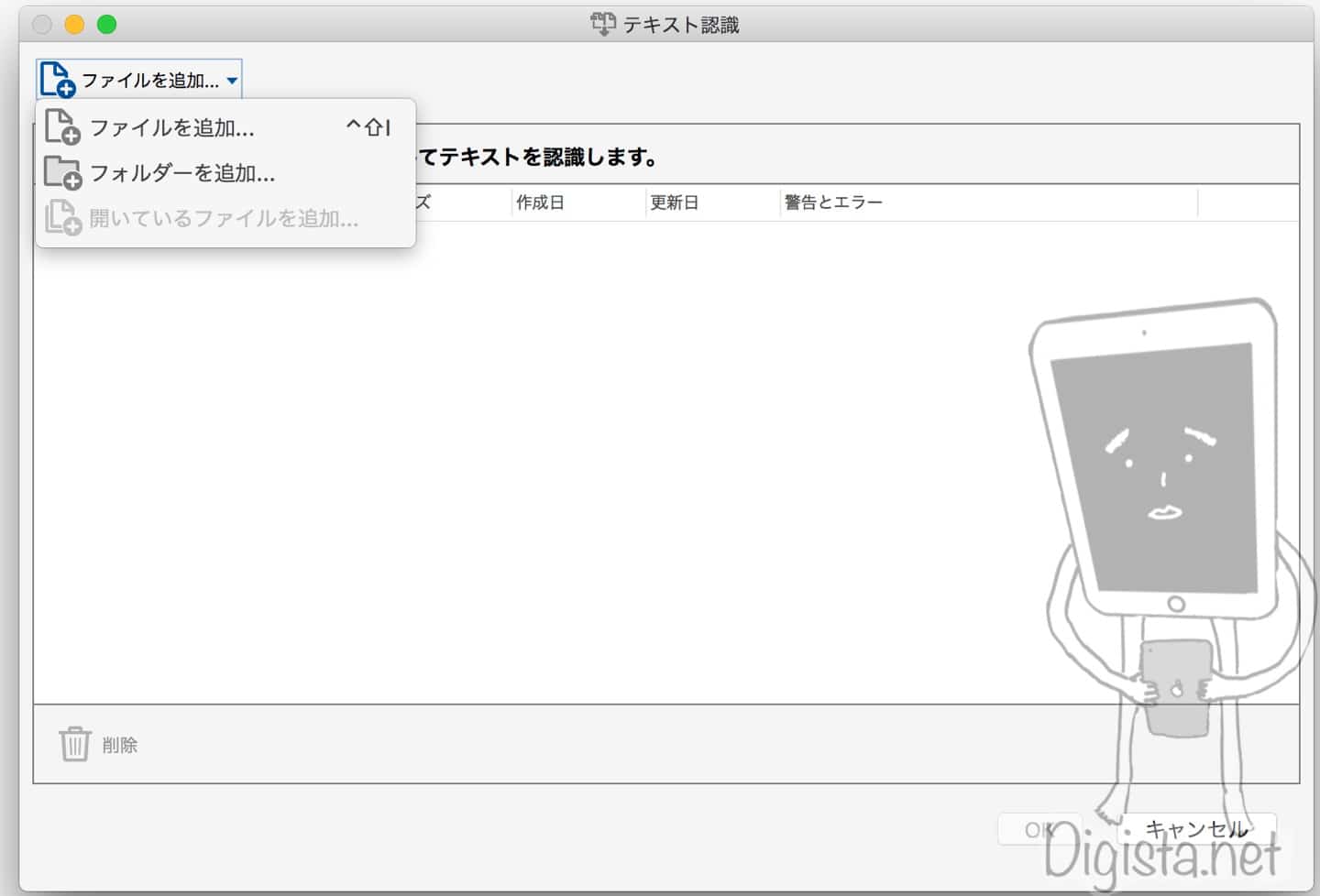
ファイルを追加するか、フォルダーまるごと追加するか選択できます。
フォルダーまるごと追加できるのが便利です。
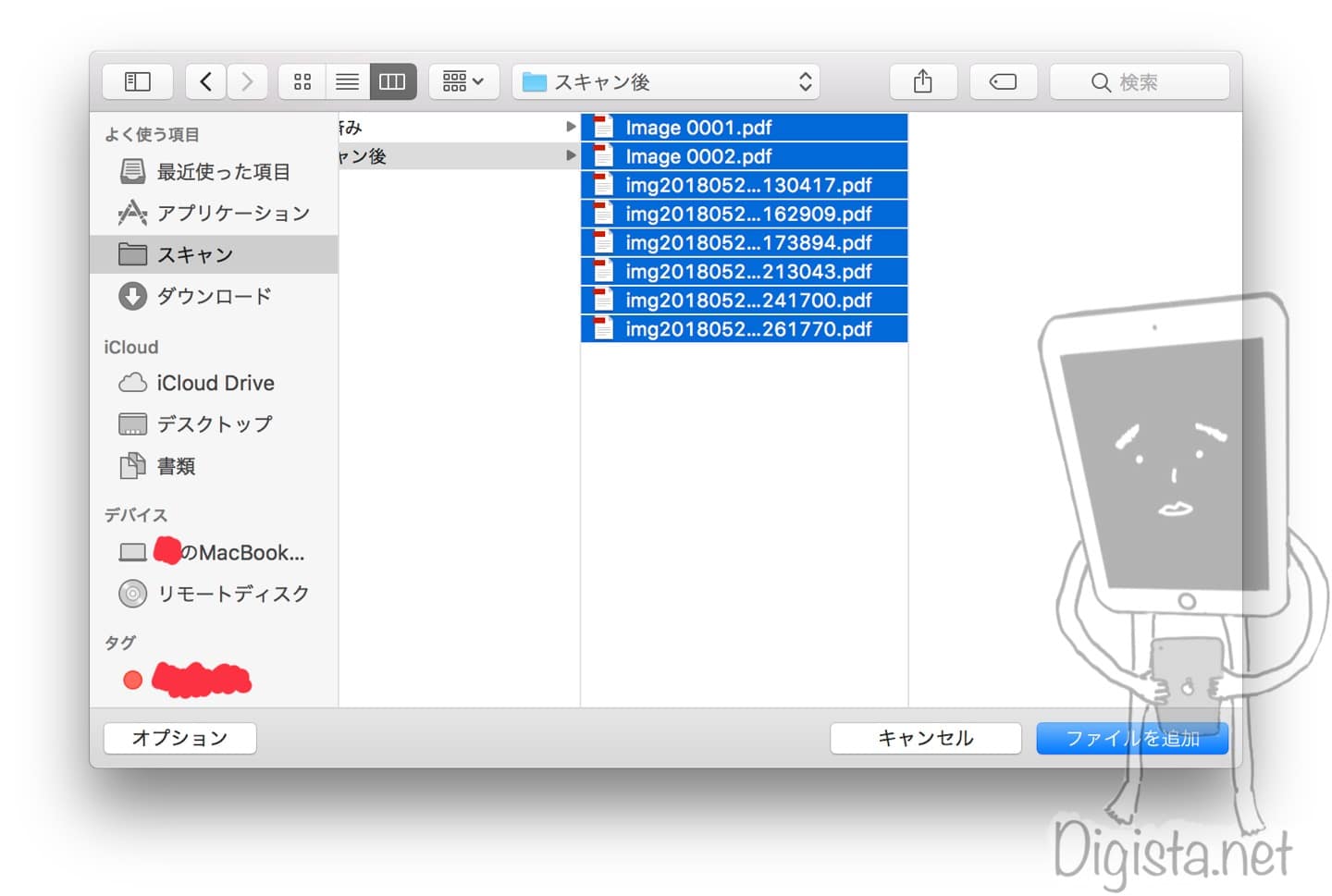
こんな感じで複数のファイルを選択していきます。
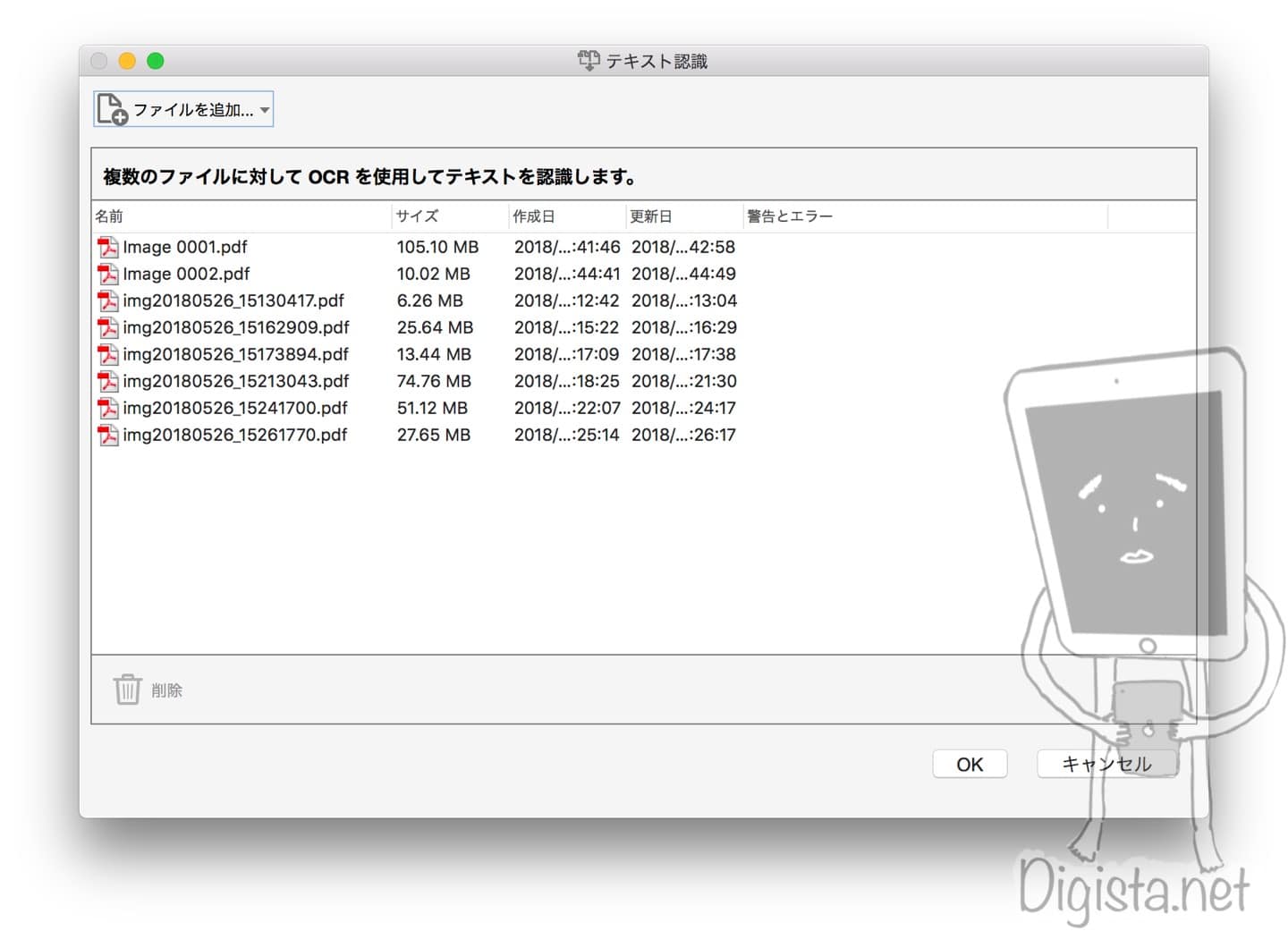
追加したファイルはこのように表示されます。
あとは「OK」を選択して文字認識を開始していきます。
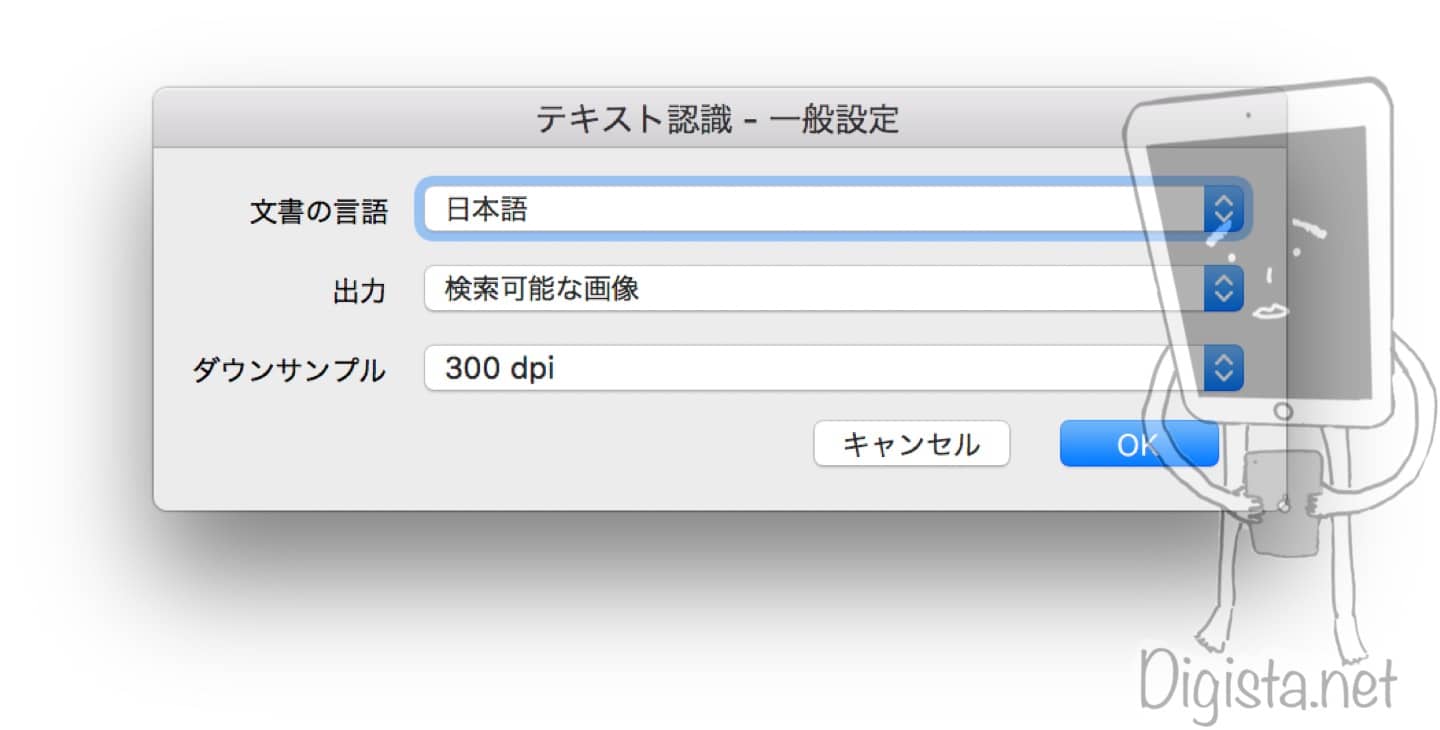
テキスト認識の設定がポップアップしてきます。
筆者はこの様な設定でテキスト認識しています。
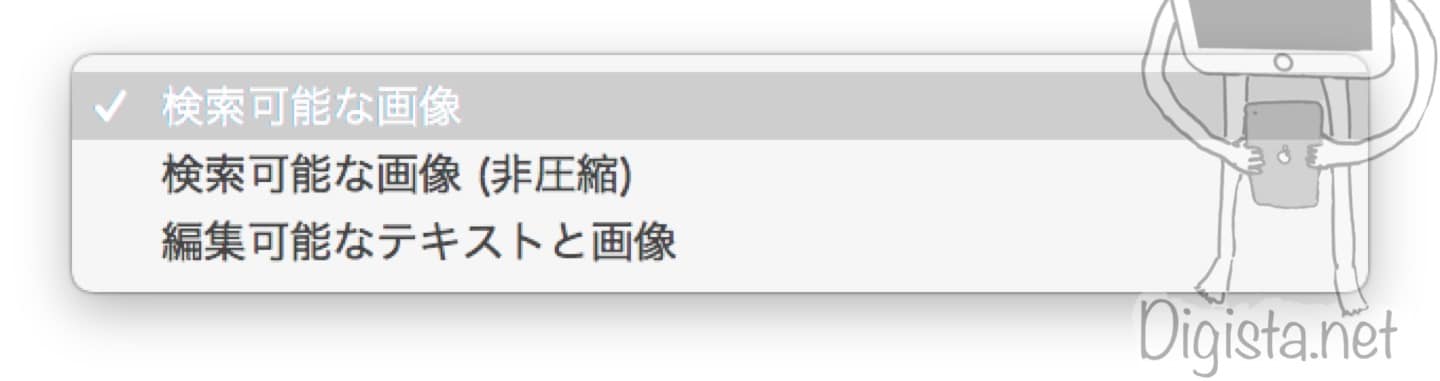
文字認識に関してはこのように3つの選択が可能です。
筆者は「検索可能な画像」で行っています。
下に「非圧縮」があることからも分かるように、「検索可能な画像」は圧縮がかかっています。
読みにくくなるわけでもなく、圧縮をかけてくれるので大変助かる機能です。
▼最後に出力先(保存場所)を決定します。
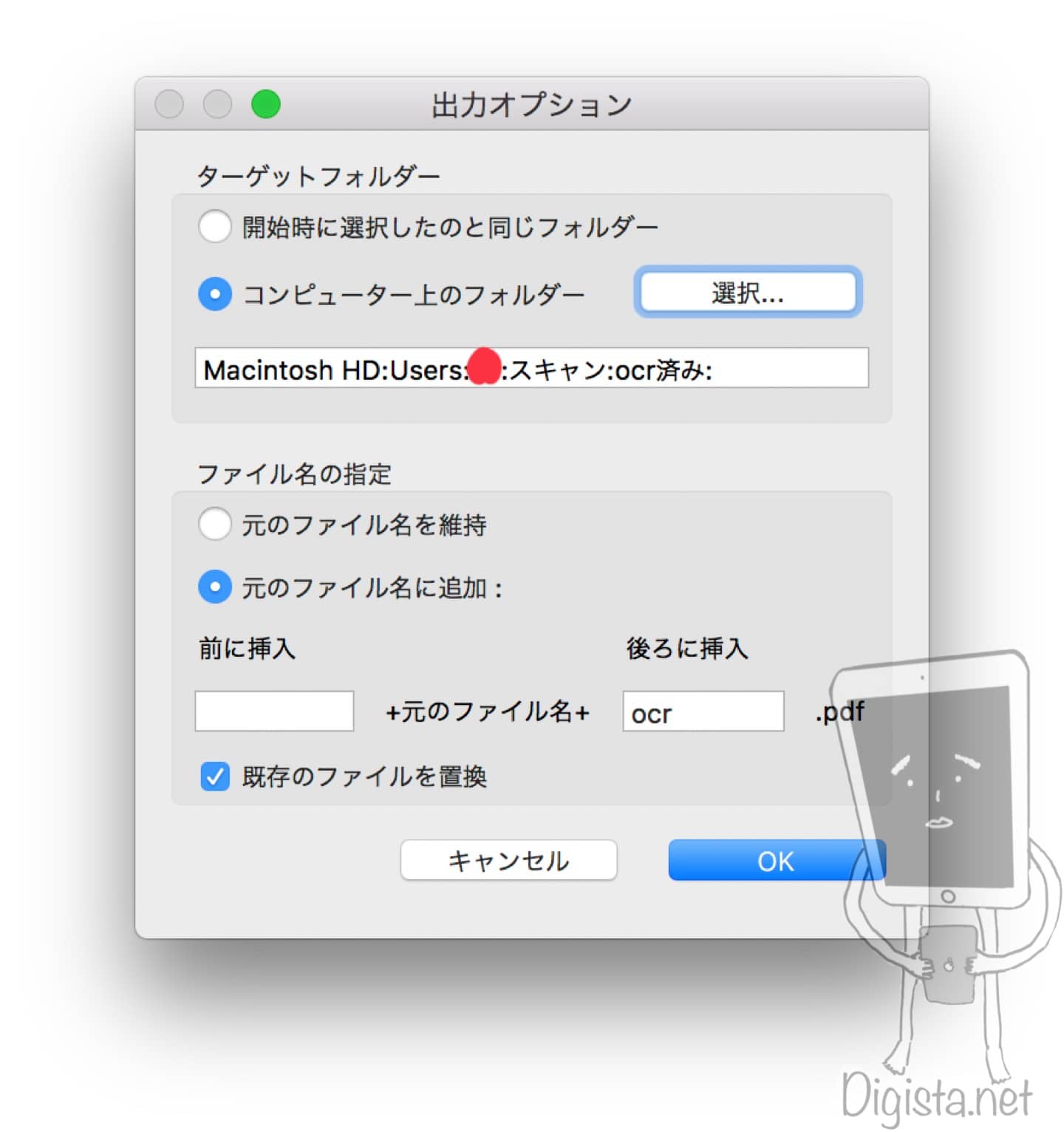
筆者の場合には
保存してくれるような設定にしています。
元のPDFと文字認識が終わったPDFは一見区別がつきにくい為です。(検索してみれば分かりますが。)
ここまでの過程でPDFが完成しました。
ここからはiPadで読むために、cloudに移動する作業です。
使用しているPDFリーダーアプリはPDF Expertです。
[applink id=”743974925″ title=”PDF Expert by Readdle”]筆者の場合はicloud上のPDF Expertのフォルダに移動しています。
序盤に紹介したように、筆者は章や内容ごとにPDFを分割して作成する方針です。
例えばハリソン内科学をPDF化した場合にはこのような感じになります。
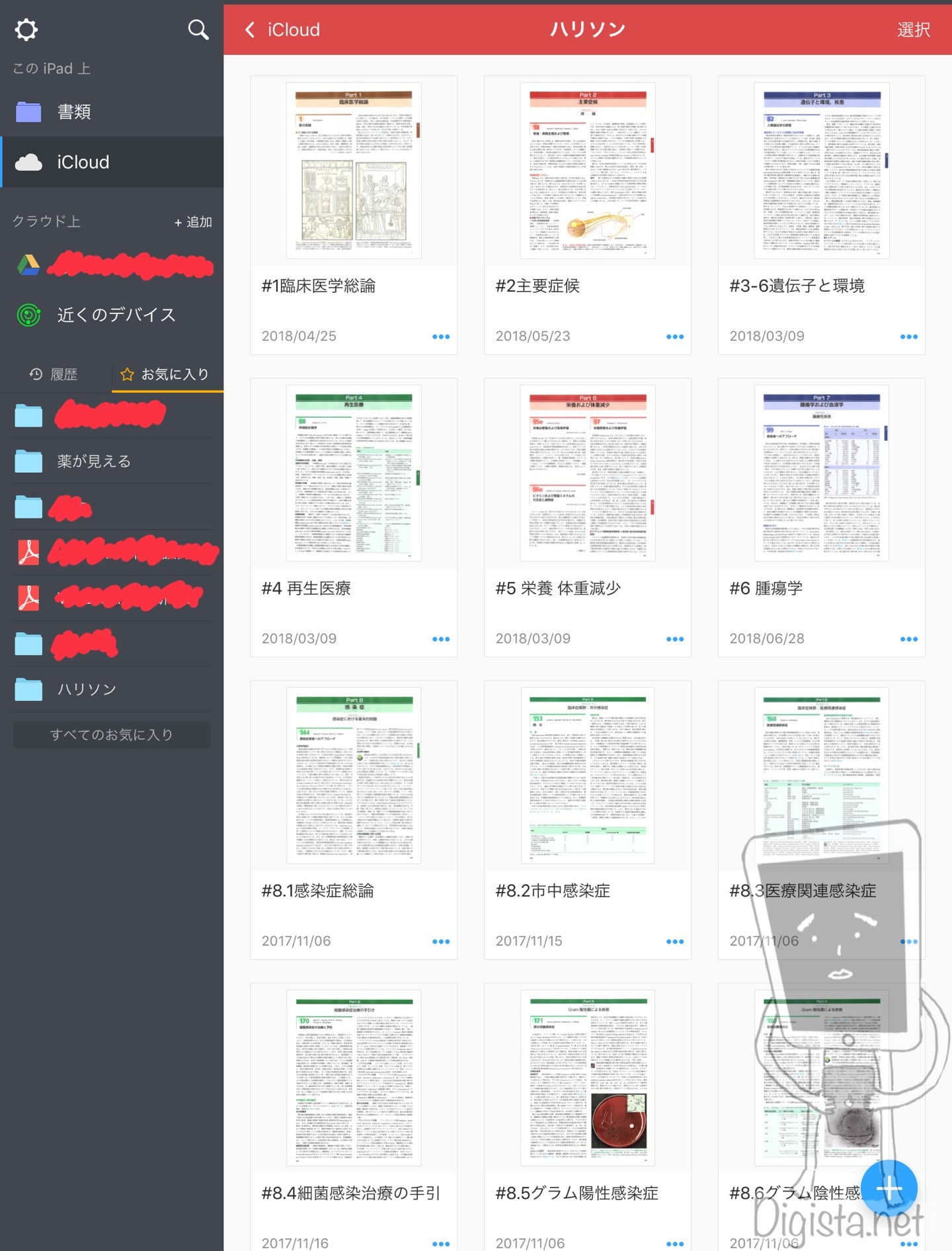
「ハリソン内科学.pdf」というファイルが一つあるよりも、読む時に便利に感じませんか?
PDF Exertでは全文検索機能もあるので、すべてのPDFから検索することも可能ですが、文字認識の精度は100%ではありません。(おそらく、どのソフトを使用しようとも)
このように大まかなジャンルごとに固まったPDFならば、本をパラパラめくるような感覚で探している内容を探すことも十分に可能です。
検索でもかなりの高確率で掛かりますけね。
でも、この方法の方が読みやすく感じるは筆者だけでしょうか?
筆者知ってますか?AmazonもApple製品公式です.
ポイントは日々変動します,今日はお得な日かも?
気になるものがあればチェック!!
iPad Pro/iPad Air/iPad/iPad mini
Apple watch SE/Apple watch/
Air Pods Pro/Macbook Air/



コメント